

12月22日Spark集群实时流式系统安装纪实,科技里程碑的诞生

背景
随着大数据技术的飞速发展,实时数据处理与分析的需求日益凸显,在这样一个信息爆炸的时代,如何高效、准确地处理海量数据流,成为企业界和学术界共同关注的焦点,Apache Spark作为一种通用的大数据处理框架,其在批处理、流处理和图计算等领域均表现出强大的能力,而其中的Spark集群实时流式系统更是成为大数据处理领域的明星技术,本文将以12月22日的一次Spark集群实时流式系统安装为例,回顾其背景、重要事件、影响以及在特定领域或时代中的地位。
重要事件
1、安装准备
在大数据处理领域,Spark集群实时流式系统的安装与部署是一项复杂而重要的任务,在前期准备阶段,技术团队需要对硬件环境、网络环境以及软件环境进行全面评估与准备,还需要对Spark集群的规模、节点配置进行合理规划,这一切准备工作都是为了确保后续安装过程的顺利进行。
2、系统安装
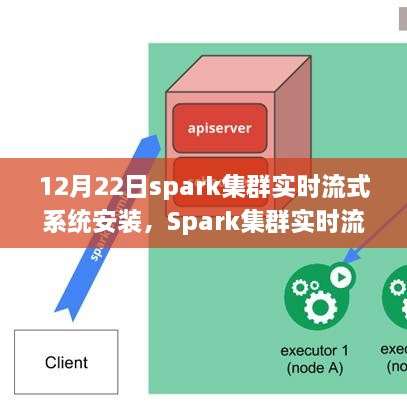
12月22日,安装工作正式启动,技术团队首先下载并解压了Spark集群的安装包,然后按照官方文档的指导,一步步进行配置,在这个过程中,技术团队遇到了不少挑战,如网络配置问题、节点间通信问题等,但经过不懈努力,最终成功解决了所有问题,完成了系统的安装。
3、系统测试与优化
系统安装完成后,技术团队进行了全面的测试与优化,测试内容包括系统的稳定性、性能、可扩展性等,在测试过程中,技术团队发现了一些性能瓶颈,并进行了相应的优化,经过多次测试与优化,最终实现了Spark集群实时流式系统的稳定运行。
影响
Spark集群实时流式系统的安装成功,对企业界和学术界产生了深远影响,它为企业提供了更高效、更实时的数据处理能力,帮助企业更好地应对市场竞争,它为学术界提供了一个研究实时大数据处理的平台,推动了相关领域的科研进展,它还为其他企业在大数据处理领域提供了宝贵的经验和技术支持。
地位
在大数据处理领域,Spark集群实时流式系统已经成为一种重要的技术手段,它不仅能够处理批量数据,还能处理实时数据流,具有很高的实时性、可扩展性和容错性,与传统的数据处理技术相比,Spark集群实时流式系统具有更高的处理效率和更低的延迟,它在金融、电商、物流等领域得到了广泛应用,随着技术的不断发展,Spark集群实时流式系统将在更多领域得到应用,成为大数据处理领域的核心技术之一。
12月22日的Spark集群实时流式系统安装,不仅是一次技术实践,更是一次科技里程碑的见证,通过这次安装,我们深刻认识到大数据技术的重要性以及实时数据流处理的紧迫性,我们将继续深入研究相关技术,为大数据处理领域的发展做出更大的贡献。
展望
随着技术的不断进步和应用的深入,Spark集群实时流式系统将迎来更广阔的发展空间,它将更加广泛地应用于各个领域,为企业的决策提供更实时、更准确的数据支持,随着技术的不断创新和优化,Spark集群实时流式系统的性能将进一步提高,延迟将进一步降低,我们期待着它在未来的大数据处理领域中发挥更加重要的作用。







 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...